Cloud native is one of the buzzwords tossed around in the developer world. What does the term mean? Here’s my take on what it should mean. Worst comes to worst, you still want to a develop an application that can be run end-to-end on your own machine?
Introduction
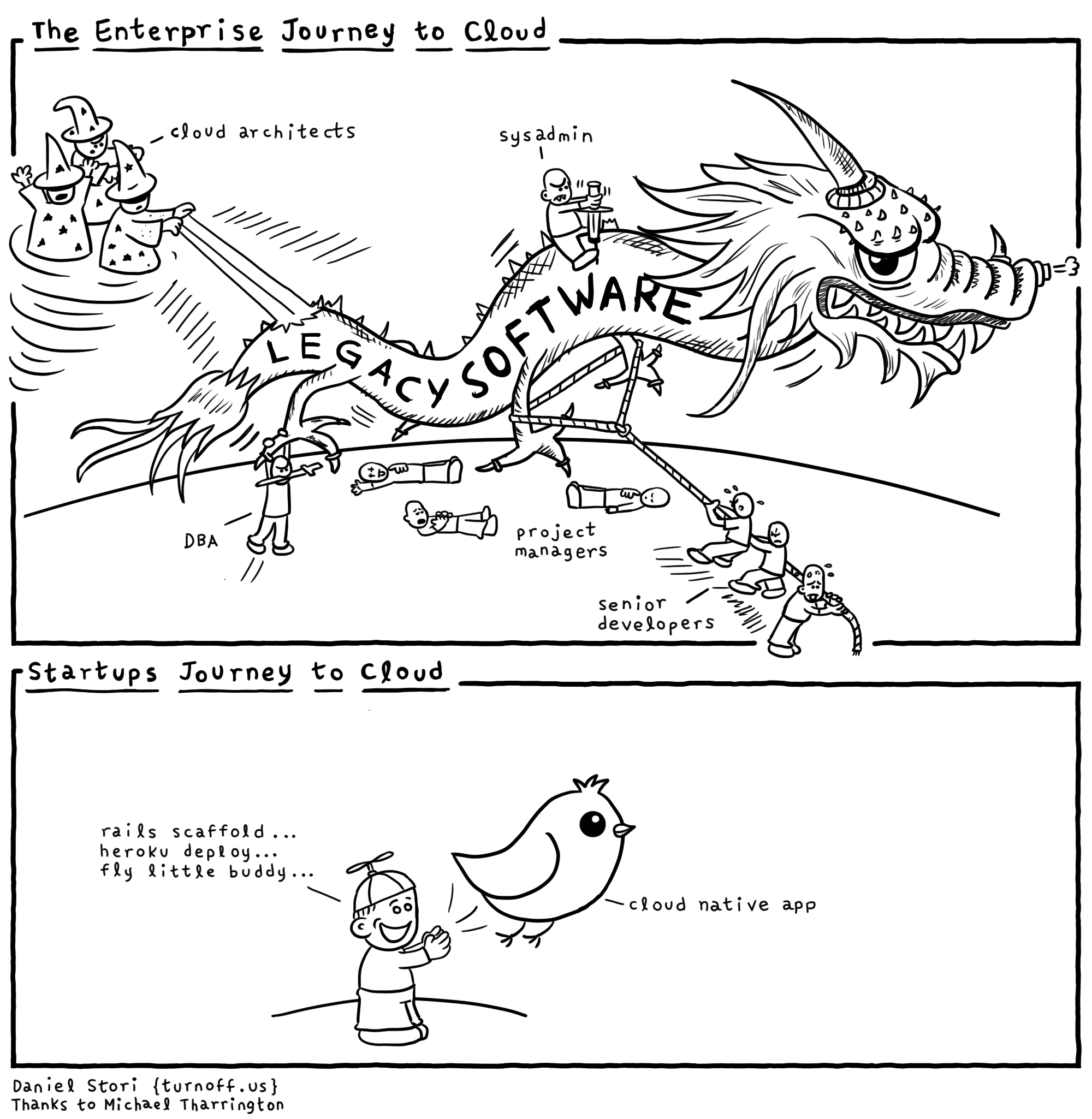
I first encountered the term cloud native when I saw a cartoon contrasting the
arduous journey of an enterprise migrating to a cloud platform versus a cloud
native startup for which deploying changes to production is merely a matter of
executing heroku deploy. I associated the term with “digital native,” which in
turn made me think about all the legacy concepts I still cling on to. To think
that some developers nowadays have not ever used a rotary dial telephone! Do they
even listen(2) anymore?
This was sometime in the 2010s. Since then, a countably infinite number of JavaScript frameworks have seen the daylight, and great many feature level bumps have been witnessed in the few software libraries that run the world. I wonder what happened to the gleeful cloud native startup given that 99% of them fail. Are we yet again facing a monster, conquerable only by a team of unicorns that bill mythical man hours?
Cloud native
In my opinion, there should be nothing vendor specific in so-called cloud native applications. To me, the term refers to a set of characteristics that an application has that make it integrate seamlessly to a cloud platform such as Amazon Web Services, Azure or Google Cloud Platform. This means things like Infrastructure-as-Code, elastic scalability based on resource utilization and, on the operations side, support for application performance monitoring (APM).

There is no exhaustive list for all the characteristics. Setting conceptual ambiguities aside, defining what cloud native means is also confounded by the fact that the cloud landscape — or should I say sky? — is changing all the time. In addition, we implement applications not for the sake of running them in the cloud but for some grander purpose. If the idea of cloud native is going to have any merit, it had better be to enable you to write the application you were asked to implement and nothing else. The cloud infrastructure should then provide solutions for the boring and tedious stuff: compute capacity, credential keystores, certificate management, log file storage…
Boring and tedious…unless you are a nerd of course.
Perhaps another way to approach the topic is to think about service availability. The root cause for unexpected service breaks during my career has been more often than not some fault in some part that is external to the software. Think log files consuming the whole hard drive as a classic example. A cloud native application done right is one that taps into the ostensibly unlimited capacity of the cloud infrastructure in an efficient way. The application then has the best changes of reaching the coveted industry-grade “five nines” (99,999%) level of availability.
In my opinion, a cloud native application gone wrong is one that is so tightly coupled to a given vendor that the application simply cannot be ported to any other environment without a complete rewrite. As always, the ease of implementing unit tests is a good indicator that tells you how well you have encapsulated the implementation details of your application. Accidental complexity in test setups and extensive use of mock objects signal that you should take out your refactoring hammer to make your application more SOLID.
Technology choices
The core technology in cloud native applications is Linux and its
cgroups(7), the magic
that makes Docker work. Now, there might
be another reincarnation of a tool like Docker in the future, but as for now,
what you do is build a Docker image and ask the cloud provider to run it. What
you get is a fully isolated runtime environment for your application, i.e. a
Docker container.
This means that the choice of a programming language or any of its frameworks is largely irrelevant from the cloud point of view. To talk to your Docker container, you end up with a server one way or another. Servers receive information from multiple clients in bursts and in parallel. Our job is to write code that keeps the server busy as long as there is something useful to do. An idling CPU is a useless CPU.
The baseline performance is naturally affected by the choice of the programming language. And from a design point of view, there is no need to rely on virtual machines like the JVM (Java Virtual Machine) if we can virtualize the execution environment with Docker. Indeed, it feels slightly silly to be writing code for a virtual machine that is running inside a virtual server — can we get real for a second?
Counting one plus one, it would then appear to be advantageous to choose a language like Rust that simply compiles down to native machine code.
However, I would argue that thinking along these lines solves a problem that does not exist. For one thing, the performance of a server application is limited by the slowest link of the network. If you can identify the runtime as a performance bottleneck, go for native code by all means. But in my experience, the big wins in server application performance are more about caching, batching and connection pooling and things of that nature. For the second, a programming language is not the same as its runtime. If need be, JVM applications can be compiled down to native code with tools like GraalVM, and a similar approach can be chosen for all the other mainstream programming languages as well.
Going serverless or not
When it comes to cloud native applications, I think the proper dimension of technology choices has to do with how serverless the application should be. As I have experience mainly with AWS, I will focus on its offerings. The three possible AWS services for running applications are:
- EC2
- AWS Fargate
- AWS Lambda
EC2 is the oldest AWS service. It enables you to provision a virtual server and take it from there. You SSH into the server and run your installation scripts as usual. Docker is an opt-in. The end result is serverless in the sense that you do not need to bother about the physical server machine.
In AWS Fargate, the whole notion of a virtual server has been abstracted away. You only specify a Docker image and the resources to allocate for running it. In AWS Lambda, you forgo even specifying the Docker image and just give AWS a bunch of scripts that should be run in response to events (e.g. HTTP request). However, you should know that AWS Lambda too is based on Docker behind the scenes: the scripts are copied to a container right when it is about to start.
EC2 is not really attractive anymore, as you end up in a situation that just like your traditional server except with the clunkiness of AWS. The decision between AWS Fargate and AWS Lambda is a difficult one. Both choices have their pros and cons.
AWS Lambda lures developers with its simple and fast development model. It’s not that different from good ol’ CGI scripting. The AWS Lambda images come equipped with the AWS SDK giving your application superpowers. It is for example trivial to send SMS messages, something I always felt fascinating.
On the scalability side, every Lambda function has a reserved concurrency limit, allowing AWS to control the amount function instances. What’s more, you only pay for the seconds of actual execution time, so you do not pay anything if there is no load. For periodic workloads, like batch jobs, the saving potential is so huge that picking AWS Lambda is really a nobrainer.
The main issue I see here is that AWS Lambda is such a proprietary platform that you end up with a vendor lock in no matter how well you layer and interface your application. The lambda scripts live in a tight symbiosis with AWS. I would not give AWS this amount of control even if things are super-duper on a clear day, especially if we are talking about a mission critical service. If the goal was to reach 99,999% availability and you or your government has beef with AWS, the level can go to 0% all too easily.
A second problem that is also related to lack of control is related to network programming fundamentals. The claim is that building on top first principles is sound engineering and leads to an end result that has the best chances to be performant and therefore cost effective. Put another way, good performance is an aspect of software that is present at every level of it. Wildly executing scripts left and right can sure lead to responsive systems, but I am not so sure about the amount of inefficiency and consequent waste that this approach entails.
I would therefore lean ultimately on AWS Fargate or any offering that has the same contract. If you’re asked to write a server, write a server. And do not make it depend on any proprietary SDK directly. Whenever possible, the dependencies should be handled by relying on standard protocols. A good example is the way applications connect to databases. Even though the database might be managed by AWS RDS, your application code does not care about this detail. It simply expects to talk SQL with some database.
Event loop as a framework
So, let’s write a server from first principles. As far as I know, the present way of thinking about servers dates back to the C10k problem coined by Dan Kegel in 1999. The advent of broadband Internet access plans revealed fundamental scaling issues with the then-prevalent approaches. Apache’s one-process-per-request and Javas Servlets’ one-thread-per-request models were both shown to have inferior scaling properties in comparison to an event loop approach.
An oldie but goodie on network performance fundamentals is this presentation by Felix von Leitner from 2003. It does not directly talk about event loops, but explains quite well the issues with other approaches. I became aware of event loops after watching Ryan Dahl’s original Node.js presentation from JSConf of 2009. The presentation is a classic and alludes to the observations present in von Leitner’s presentation. I might also point to the chapter on nginx in The Architecture of Open Source Applications as nginx was one of the first projects to go mainstream with the event loop approach.
I am not going to explain how to program an event loop. I’ll just point to
this guide
and this presentation. Both of
these refer to NodeJS/JavaScript but the ideas are fundamentally language
agnostic. In essence, it is possible to tell the operating system to execute a callback
function whenever a TCP socket receives bytes from the network. The relevant
syscall family in Linux goes by the name of
epoll(7).
The fundamental part here is that there is a natural inversion of control (IoC) when it comes to server software. Instead of “as a software architect, it is my responsibility to come up with a scalable system”, you think “I have a chunk of bytes from a client. What happens next?”. The shift in thinking is literally about having the network and ultimately the thought processes of human beings drive the control flow of the server.
I have read many blogs posts about if you really need a software framework for implementing the application you have been asked to write. When it comes to servers, the answer is resounding yes. What you need is a framework with an event loop. It is the only honest way to implement servers.
The scaling properties of the event loop approach are just phenomenal. And to top it all, the event loop callback queue can be executed on a single thread. This completely obviates concurrency hazards that plague many multithreaded server applications. As long as the callbacks are chained together in the correct order and execute individually fast enough, the server keeps on churning requests to responses in a highly asynchronous manner.
I have been a fan of NodeJS throughout my career and I can finally point out the reason. You see, JavaScript has had a specification of an event loop from day one, as it was originally meant to spice up web browsers. As pointed out in e.g. Brian Goetz’s Java Concurreny in Practice, nobody has figured out how to write a robust GUI framework without an event loop.

However, it was the brilliant realisation of Ryan Dahl that he could take the
specification of the JavaScript event loop and stick the epoll(7) bits in
there. The elegance of this is that event loop framework is already baked in the
NodeJS runtime itself and you do not have to patch the language with a library
as with all the other mainstream languages.
Concluding remarks
In this blog post I put together some of the ideas I have developed over the years about programming in the cloud and servers in general. My AWS journey began in 2018, and perhaps an overarching lesson has been that fire is a good servant but a bad master as the Finnish expression goes.
It is all too easy to give cloud providers too much control of your application, and I do not particularly like the way in which governments are sleeping at the helm when it comes to their national ICT infrastructure. And I hope that the codebase of the startup of the 2010s is clean — even though I have my doubts.
Be it as it may, engineering like life is about finding a balance. In truth, I find the idea of application containerization so natural that I have difficulties thinking about my job without it. Perhaps I am a digital native in the end?